
Рвав-рвав, здесь и сейчас с вами собака Смайл!
Для начала немного о том, почему я грустный:
Санкт-Петербург, дождь, грязюка, холоднюка.
Приходится носить всякую фигню. Сопротивление бесполезно. Надеюсь, вы тоже мучаетесь, так как вместе - веселее.
Сегодня хотелось бы описать работу с так называемой "сломанной" иерархией данных. В принципе, это довольно часто встречающаяся ситуация, из которой каждый выходит так, как может, но собака Смайл в данной статье постарается разъяснить все доступным языком. Так сказать, "Повторение - мать учения".
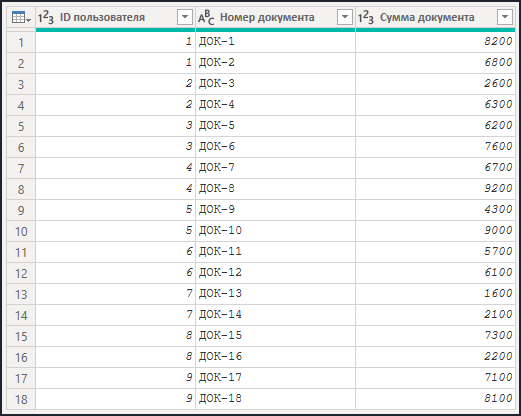
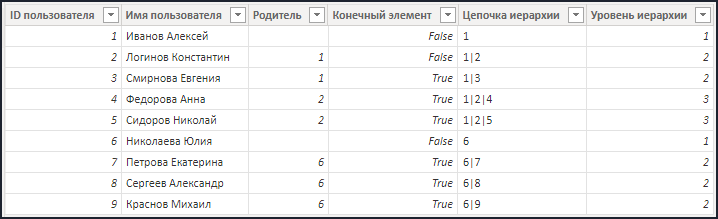
- Таблица "Перечень документов" содержит основные сведения об имеющемся наборе документов компании, а именно ID пользователя, номер документа и сумму документа:
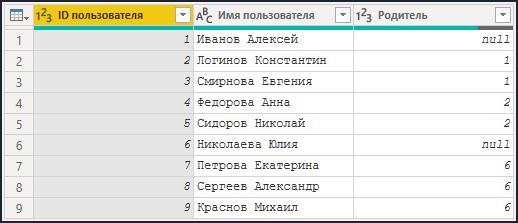
- Справочник "Иерархия сотрудников", содержащий информацию о структуре подчинения между сотрудниками:
Задача:
- На основе представленных данных построить иерархию данных таким образом, чтобы у каждого сотрудника было одинаковое количество уровней иерархии, а также убрать повторяющиеся значения на разных уровнях иерархии, то есть, произвести ее "схлопывание".
Построение структурированной иерархии в справочнике "Иерархия сотрудников":
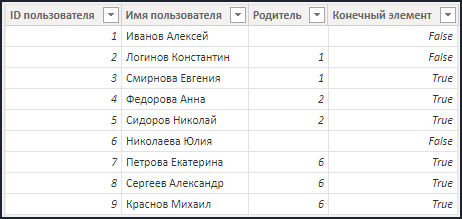
- В целях устранения хаоса в исходных данных для начала нам необходимо понять, является ли конкретное значение конечным элементом иерархии. В этом нам может помочь столбец "Конечный элемент". В принципе, делать его необязательно, но в случае большого объема данных он сможет помочь при проверке конечного результата:
Формула указанного столбца выглядит следующим образом:
Конечный элемент =
CALCULATE (
COUNTROWS ( 'Иерархия сотрудников' ),
ALL ( 'Иерархия сотрудников' ),
'Иерархия сотрудников'[Родитель]
= EARLIER ( 'Иерархия сотрудников'[ID пользователя] )
) = 0
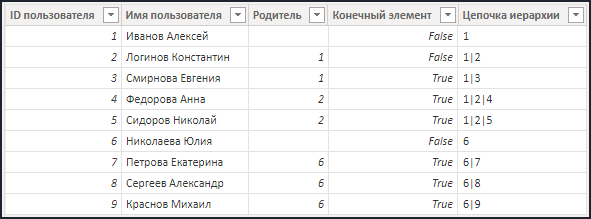
- Следующим шагом является построение цепочки родительских значений, для последующего определения уровня иерархии. В этом нам поможет столбец "Цепочка иерархии", рассчитанный при помощи функции "PATH":
Формула указанного столбца выглядит следующим образом:
Цепочка иерархии =
PATH (
'Иерархия сотрудников'[ID пользователя],
'Иерархия сотрудников'[Родитель]
)
- Подсчет уровня иерархии, проиллюстрированный в столбце "Уровень иерархии", можно произвести при помощи функции "PATHLENGHT":
Уровень иерархии =
PATHLENGTH ( 'Иерархия сотрудников'[Цепочка иерархии] )
- Выполнив указанные шаги, можно приступать непосредственно к построению уровней иерархии при помощи функций "PATHITEM" и "LOOKUPVALUE":

Формула столбца для 1-го уровня иерархии – столбец "1-й уровень иерархии", представляет собой следующую конструкцию:
1-й уровень иерархии =
LOOKUPVALUE (
'Иерархия сотрудников'[Имя пользователя],
'Иерархия сотрудников'[ID пользователя],
PATHITEM (
'Иерархия сотрудников'[Цепочка иерархии],
1,
INTEGER
)
)
Формула столбца для 2-го уровня иерархии – столбец "2-й уровень иерархии", представляет собой следующую конструкцию:
2-й уровень иерархии =
IF (
'Иерархия сотрудников'[Уровень иерархии] >= 2,
LOOKUPVALUE (
'Иерархия сотрудников'[Имя пользователя],
'Иерархия сотрудников'[ID пользователя],
PATHITEM (
'Иерархия сотрудников'[Цепочка иерархии],
2,
INTEGER
)
),
'Иерархия сотрудников'[1-й уровень иерархии]
)
Формула столбца для 3-го уровня иерархии – столбец "3-й уровень иерархии", представляет собой следующую конструкцию:
3-й уровень иерархии =
IF (
'Иерархия сотрудников'[Уровень иерархии] >= 3,
LOOKUPVALUE (
'Иерархия сотрудников'[Имя пользователя],
'Иерархия сотрудников'[ID пользователя],
PATHITEM (
'Иерархия сотрудников'[Цепочка иерархии],
3,
INTEGER
)
),
'Иерархия сотрудников'[2-й уровень иерархии]
)
Собственно, первая цель по построению иерархии, выравненной автоматическим путем, на этом закончена, единственное, с чем надо определиться – это с необходимым количеством уровней, поскольку для каждого уровня требуется отдельный расчетный столбец.
Визуализация данных – стандартное поведение иерархии:
- Используя стандартный элемент "Матрица", мы можем "соединить воедино" данные справочника "Иерархия сотрудников" и основного набора данных – таблицы "Перечень документов". Визуальный элемент будет выглядеть следующим образом:
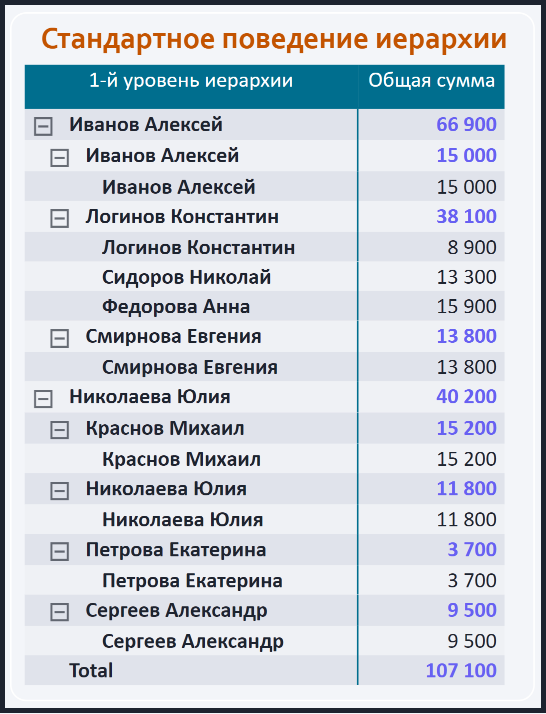
При построении матрицы в иерархическом дереве присутствуют дубли в имени сотрудников. Это объяснимое поведение, поскольку "оно так работает", однако повторяющиеся значения можно убрать, используя "дополнительные приседания", а именно – соответствующие меры.
Визуализация данных – схлопывание иерархии:
- Для достижения 2-й поставленной цели нам необходимо рассчитать несколько мер, начиная с определения нижнего уровня вложенности:
Глубина значения =
ISFILTERED ( 'Иерархия сотрудников'[1-й уровень иерархии] )
+ ISFILTERED ( 'Иерархия сотрудников'[2-й уровень иерархии] )
+ ISFILTERED ( 'Иерархия сотрудников'[3-й уровень иерархии] )
- Место каждого сотрудника в иерархическом дереве определяется при помощи следующей конструкции:
Значение иерархии =
MAX ( 'Иерархия сотрудников'[Уровень иерархии] )
- Расчет суммы по каждому участнику производится по формуле:
Промежуточный расчет =
IF (
[Глубина значения] > [Значение иерархии] + 1,
BLANK (),
IF (
[Глубина значения] = [Значение иерархии] + 1,
IF (
AND (
VALUES ( 'Иерархия сотрудников'[Конечный элемент] ) = FALSE,
SUM ( 'Перечень документов'[Сумма документа] ) <> 0
),
SUM ( 'Перечень документов'[Сумма документа] ),
BLANK ()
),
SUM ( 'Перечень документов'[Сумма документа] )
)
)
- Устранение дубликатов в иерархическом дереве со сдвигом промежуточных итогов реализуется следующим образом:
Конечный расчет =
IF (
[Глубина значения] > [Значение иерархии],
BLANK (),
SUM ( 'Перечень документов'[Сумма документа] )
)
Визуализация данных – настроенное поведение иерархии:
- Используя стандартный элемент "Матрица", и поставив в качестве значения меру "Конечный расчет" мы можем получить правильный, а также приятный глазу результат:
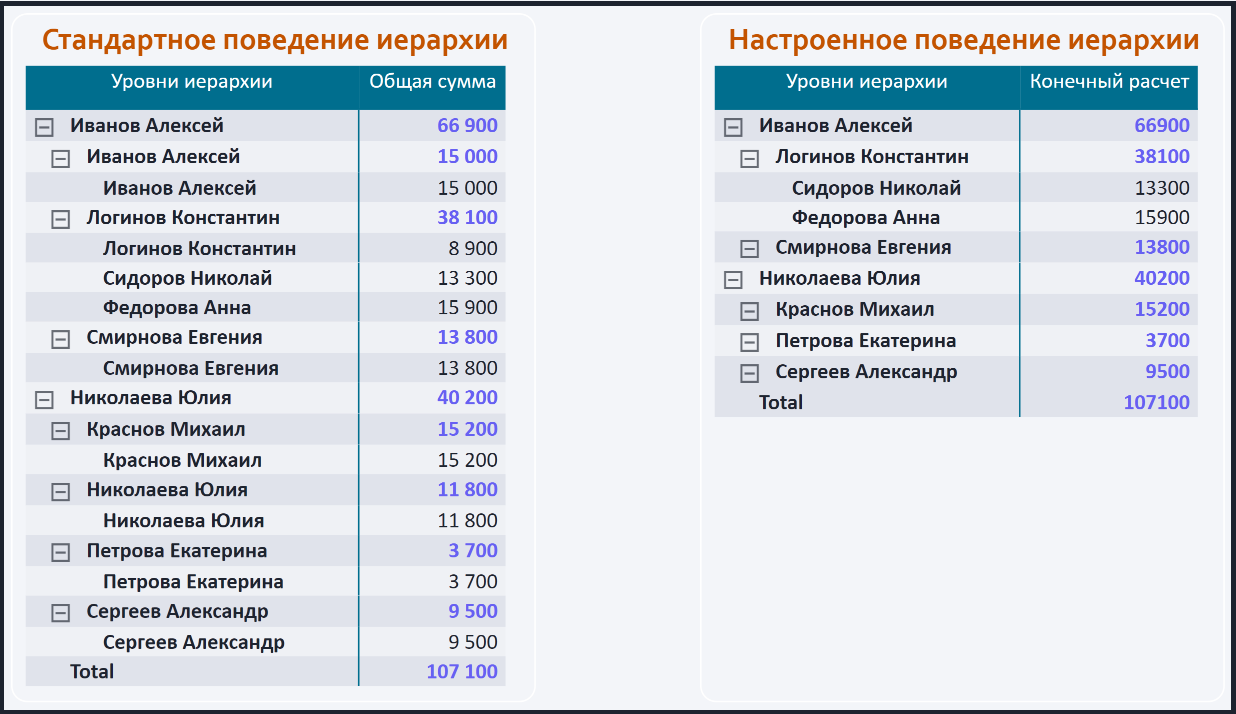
При этом суммирование по уровню иерархии, так называемые промежуточные итоги, включает в себя как подчиненные элементы, так и свое собственное значение.
Рвав-рвав, наконец-то конец, до новых встреч в Новом году!
Ваш Смайл